What are the best servers to run Microsoft Hyper-V?
Hyper-V is a server virtualization software developed by Microsoft Corporation that virtualizes a single hardware server into multiple virtual servers/machines. (Learn more about Hyper-V in our post, These are the 8 best use cases for Microsoft Hyper-V.) Each virtual machine runs as an isolated logical unit/partition and the underlying hardware resources (processor, hard drive, memory, etc.) of the host server are shared between the virtual machines.
Microsoft Hyper-V is available in the following three variants:
- Hyper-V for WIndows Server: An optional add-on to the Windows Server Family that includes Windows Server OS licenses for guest VMs as well (See Servers Direct for details).
- Hyper-V Server: A stand-alone, stripped-down and command line interface (CLI)-based version of Hyper-V with no included licenses for guest VMs.
- Client Hyper-V: This is the streamlined version of Server Hyper-V for individual desktops and machines.
Hyper-V offers a number of benefits. Key use cases include maximizing the usage of hardware resources, minimizing downtimes by offering live migrations and failover clustering, and reducing data center footprints. It also assists the IT teams by increasing their productivity, improving manageability, and enabling R & D and troubleshooting.
Let us now explore the optimum hardware that can be used to run Microsoft Hyper-V.
Minimum hardware requirements to run Hyper-V
Hyper-V has the following system requirements listed as a minimum:
- 64-bit processors with Second Level Address Translation
- Minimum 4 GB memory
- Virtualization support enabled in BIOS/UEFI
While hardware enforced Data Execution Prevention is also listed as a requirement, most of the modern CPUs will have this feature by default.
The hardware requirements listed above are fairly basic and any system that meets these criteria can become the host server for Hyper-V installation. However, in order to get the most out of a Hyper-V enabled environment, there are further hardware considerations that need to be evaluated. Since the host server’s physical hardware resources like CPU, memory, and network limit the performance of guest VMs, it is important to design and scale these resources accordingly. Let’s explore this in further detail.
CPU
While the speed of the CPU is important, it is actually the number of cores that improve the performance of VMs. The greater the number of cores and threads, the faster the VMs will be able to perform.
It’s important to maintain a certain correlation between the number of cores on the host machine and the vCPUs on the guest OS. Physical compute power should neither be under-provisioned nor over-engineered. For most workloads, a physical to vCPU correlation of 1-to-8 or 1-to-12 will suffice. Processors with higher caches will also boost performance.
Memory
Because the guest virtual machines run in memory, the physical RAM of the host server can directly impact the VM’s performance. Mission critical VMs should be allocated a greater memory compared to a non-intensive application like a mailserver.
While sizing the memory, it is important to remember that Hyper-V itself will have a memory overhead of 2-3% and the host OS should also have 2-4 GB memory available. So for example, if 5 VMs are deployed on a server and each VM requires 2GB memory, the host server should at least have 16GB RAM. Overloading the server with a greater number of VMs or fitting the server with a greater RAM will not be a good choice in this case.
Storage
While storage is not exactly a hardware bottleneck, it has to be sized rightly to ensure enough space is available for files and data of both the host and guest OS. The total disk space is dependent on the expected cumulative size of all systems combined. A data growth rate for each VM/application should also be factored into the sizing. RAID configurations, higher spindle counts, greater RPMs, and the option to go for SSDs will improve the performance.
Network
Although network adapter is not listed as a hardware requirement, it is obvious that all the traffic of the host server and the guest VMs will transit from the available physical network interface. It is generally a good practice to have two network adapters—one is dedicated for the host OS while the second is shared among the VMs. In case a traffic-intensive workload is expected for a particular VM, another dedicated network interface might be considered. 2 x 10 Gig Ethernet/SFP should be taken as a minimum will a quad port card can be considered for greater network traffic.
Which whitebox servers are best for Hyper-V?
Whitebox servers have been a popular choice in the Data Center industry for a long time and have consistently held a solid share in terms of number of units shipped as well as overall server revenue. Cloud service providers tend to tilt more towards whitebox servers as compared to enterprise clients or telcos.
Ease of customization and configurability, lower cost of ownership and ease of maintenance/support by virtue of using standard hardware modules are the key reasons for adopting whitebox servers over branded systems. The rise of virtualization use cases (see Why White Box Servers Beat the Big Brands) have further increased the popularity of whitebox servers. We have shortlisted two server families from our Ultra Server series to explain why they are the most suitable hardware to run virtualized workloads. Let’s take a look at the hardware configuration options for 1029 and 2029 Ultra Server series:
Hardware Consideration
|
1029 Family |
2029 Family |
CPU
|
Dual Socket P (LGA 3647)
2nd Gen Intel® Xeon® Scalable Processors and Intel® Xeon® Scalable Processors‡,
Dual UPI up to 10.4GT/s |
Dual Socket P (LGA 3647)
2nd Gen Intel® Xeon® Scalable Processors and Intel® Xeon® Scalable Processors‡,
Dual UPI up to 10.4GT/s |
Memory
|
Configurable from 8 GB DDR up to 6 TB |
Configurable from 8 GB DDR up to 6 TB |
Network
|
Configurable from 4xGbE up to 4x10GBaseT |
Configurable from 4xGbE up to 4x10GBaseT |
Storage
|
10x 15TB Hot Swap Drive Bays for NVME, SAS/SATA or SSD drives in multiple configurations |
24x 15TB Hot Swap Drive Bays for, NVME SAS/SATA or SSD drives in multiple configurations |
Additional Considerations
|
- 8 Port SAS3 HBA 12Gb/s with HW RAID Controller
- 32 GB NVIDIA GPU
- 3 Year Warranty
- Choice of Multiple OS
|
- 8 Port SAS3 HBA 12Gb/s with HW RAID Controller
- 32 GB NVIDIA GPU
- 3 Year Warranty
- Choice of Multiple OS
|
- Both 1029 and 2029 provide dual CPU sockets with multiple CPU options to provide upto an overall 56 cores/112 threads capacity. Considering a physical to vCPU correlation of 1-to-8, these servers can provide 416 vCPUs (assuming 4 physical cores are dedicated for the host OS). The available 416 vCPUs can be used to architect a great number of possible VM configurations, for example 104 VMs with 4 vCPUs each or 52 servers with 8 vCPUs each or any combination thereof. A physical to vCPU correlation of 1-to-12 for non-intensive workloads can further increase these numbers.
- These server families can support upto 6TB of physical memory providing enough memory to be allocated to the VMs without hitting performance bottlenecks.
- 1029 server family has 10 drive bays with a maximum drive size of 15 TB each. This amounts to 150TB of total storage space. 2029 increases the number of drive bays to 24 which increases the total storage size to 360 TB. This provides adequate storage distribution options for the guest VMs. Both 1029 and 2029 series also have the option of SSD for improved read/write speeds.
- Both 1029 and 2029 series also provide the option to add NVIDIA GPU for increased graphical or computational workloads.
- Both server families come with a standard three year warranty which can be further enhanced to extended or on-site support.
Conclusion
1029 and 2029 server families score well among all the hardware considerations mentioned earlier in the article and the available configuration options cater to a very wide range of possible requirements. From hosting a few VMs to 100 plus VMs, these server families can scale well to serve a diverse set of workloads. Considering the configuration options, extensibility and scalability, and value for money and support, 1029 and 2029 Ultra Server series are among the best server hardware to run a virtualized environment. You can read more about these server families here.
The 8 Best Use Cases for Microsoft Hyper-V
What is Hyper-V?
Hyper-V is Microsoft software that virtualizes a single hardware server into multiple virtual servers/machines.
Hyper-V lets you share the underlying hardware resources (processor, hard drive, memory, etc.) across virtual machines (VMs) by assigning them virtual resources. Each VM then becomes capable of running its own operating system and applications.
Hyper-V forms a layer of abstraction between the underlying hardware and the virtual machines. It then assigns the allocation and management of these hardware resources to the guest operating systems. It makes logical units of isolation or, “partitions”, in the host server which are then used to create virtual machines.
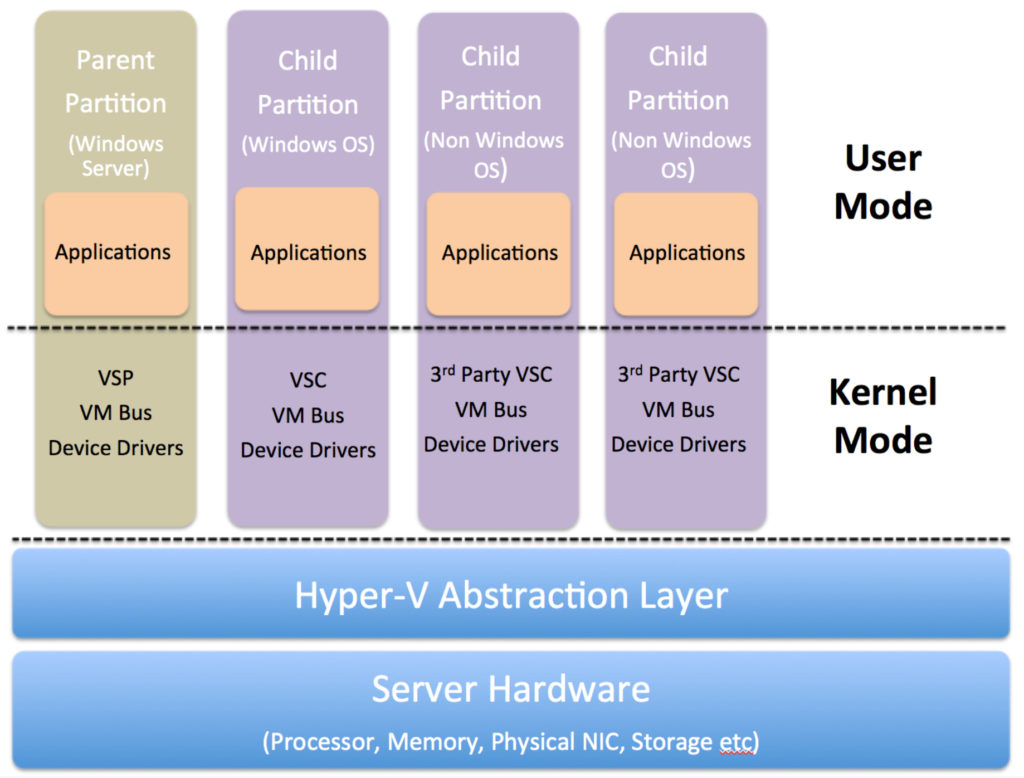
The host Windows OS runs in the parent names as parent partition or root. Hyper-V runs directly on the host hardware and manages the OS running on the server. Even the host operating system runs on top of Hyper-V. However, unlike the guest operating systems, the host OS has direct access to the hardware resources.
The first version of Hyper-V was introduced in Windows Server 2008 and has since been released with every version of Microsoft Windows Server. Currently, there are three variants of Hyper-V:
Hyper-V for Windows Server
This is an optional add-on to the Microsoft Windows Server Operating System (Essentials, Standard, and Datacenter Editions). There is no licensing fee to use this add-on, however, there are additional licensing rules with regards to the number of guest VMs running Windows Server OS.
With the Standard Server, up to two VMs can run Microsoft Standard Server OS while the Datacenter edition gives the right to use any number of Windows Server OS on the guest VMs. For any other operating system, the licensing rules pertaining to that particular OS apply.
As long as the above mentioned licensing rules are followed, up to 1024 VMs can be created.
Hyper-V Server
This is a stand-alone free download of Hyper-V from the Microsoft Download Center. But there are limitations with Microsoft Hyper-V Server. It offers no graphical user interface (GUI) and works through Command Line Interface only. Unlike Hyper-V for Windows Server, it lacks a centralized management tool/console. As you might expect for a free download, there are no Windows VM licenses included.
Client Hyper-V
Client Hyper-V is a trimmed down version of the Server Hyper-V, which lets you create VMs on laptops and desktop machines. Since Windows 8, client Hyper-V has remained a part of Windows Desktop operating systems (Professional and Enterprise Editions).
IT professionals and developers often use Client Hyper-V to create test environments on their individual machines to test software on multiple OS. They can also use Client Hyper-V to troubleshoot production environments by exporting VMs on their devices, or configuring a Hyper-V virtual machine and then exporting it onto a production server.
When to Use Hyper-V
Let’s take a look at some of the top use cases for Microsoft Hyper-V:
1. Maximize Hardware Usage
Hypervisors arose from a need to utilize idle hardware resources. Most server hardware configurations are sized to handle maximum workloads during peak demand periods. Therefore, during off-peak hours many hardware resources are underutilized or idle.
One of Hyper-V’s primary use cases is to maximize this additional hardware capacity by consolidating workloads. This in turn increases the return on investment (ROI) for hardware expenditure.
2. Increase Efficiency and Productivity
Quick response times and shortened time to market are key drivers for all businesses. IT teams are expected to respond quickly to server deployment requests in order to provision new services and applications. Hyper-V can shorten delivery time by making use of already-deployed hardware and running virtual machines on top of them.
Hyper-V can also rapidly commission temporary environments. These environments not only include test, development, and sandbox environments but also training and demo environments for internal and external audiences.
3. Minimize Downtime
In a world where businesses are expected to deliver uninterrupted services round the clock, IT teams need to minimize both planned and unplanned downtime. Quick/live migrations and server portability are essential to meeting business continuity key performance indicators (KPIs). Hyper-V can quickly move workloads to new hardware to address these requirements.
The Failover Clustering feature ensures business continuity in the event of a disaster. Additionally, by using Hyper-V Replica functionality a production VM can easily be cloned by creating a backup image. This feature not only comes handy in the occurrence of an outage but can also be used before making any configuration changes to a production VM.
4. Reduce Data Center Footprints
By consolidating workloads on virtual servers, Microsoft Hyper-V can reduce the actual number of physical servers in a data center. This means there will be less heating, cooling, and space requirements resulting in direct cost savings. Smaller datacenter footprints also align your business with “Green IT” environmental initiatives.
5. Enable VDI Environment
Developers often work on assignments with high compute workloads that overwhelm their laptops or desktops. Hyper-V’s Virtual Desktop Infrastructure (VDI) environments can cater to these high-compute workloads.
By consolidating high performance virtualized workstations in the data center, distributed teams can access a centrally managed and secured environment that developers can use to run their workloads.
6. Improve Manageability
Hyper-V is used to centralize the management and administration of the consolidated server farms. Providing a single management console enables efficient administration and control of all the VMs across a data center. Automated management tasks and bulk actions reduce the amount of time spent in conducting system administration related activities.
7. Reduce Licensing Requirements
For companies already using Windows Servers, Hyper-V provides a low-cost virtualization option since there are no additional licensing requirements. Every Windows Standard Edition Server can host two guest VMs running Server Edition or lower while the Windows Datacenter Edition Server can host up to 1,024 Windows VMs without incurring any additional licensing.
8. Enable R&D and Troubleshooting
Developers are often required to test out their applications on a variety of infrastructure configurations and operating systems. Similarly, support engineers have to repeatedly recreate specific scenarios and environments to test out a bug or perform troubleshooting activities.
Hyper-V lets developers and support engineers quickly set up virtual environments, test out the applications, or perform troubleshooting, and just as quickly take down the VMs when they’re done.
Conclusion
Virtualization’s benefits improve ROI, reduce hardware footprints, and boost enterprise performance and efficiency, making it an essential piece of every IT strategy. Contact Servers Direct to talk to an expert about the best way to virtualize your enterprise servers.
Want to learn more about the best hardware platforms to maximize Microsoft Hyper-V benefits? Check out, These are the best servers for Microsoft Hyper-V to learn what criteria are critical for selecting Microsoft Hyper-V hardware platforms.
How to buy the right Supermicro Server
5 Steps to Help You Buy the Right Supermicro Server
Servers power much of our modern world. Likely you’ve used multiple servers in the last few hours. But, since they do most of their work in the background, many of us don’t give them a second thought. Even in an enterprise environment where the value of modern servers is better understood, we may take them for granted.
How does this mindset affect organizations? It may mean that server technology isn’t updated as frequently or that the power consumption of your setup may be costing your organization thousands of dollars. But, there are more subtle ways that servers can improve or hurt your bottom line. We’re living in an age where experience is everything, and customers have no qualms about jumping ship from a service provider that is unreliable or has poor performance due to outdated or under-specced servers.
Organizations that take customer experience seriously will ensure that their technology meets customer demand and allows room for future growth.
Why Buy Supermicro Servers?
In the past, hardware and software were locked together. This meant that in order to get quality server equipment an organization had to commit to a big brand, and with that came a hefty price tag.
This changed with the advent of the software-defined data center (SDDC). Through virtualization, organizations could run many different types of software on a variety of hardware, effectively ending the need to depend on proprietary hardware.
By leveling the playing field through virtualization, server companies like Supermicro could now go head-to-head with their big brand competition, like HP and Dell. Consider some pros and cons of choosing a Supermicro vendor over its big brand competitors.
Cons
- Some Supermicro vendors only offer limited support. Big brand servers typically come with advanced support services not always provided by Supermicro vendors.
- Limited access to big brand software. Big brand servers may include proprietary management tools not available with other hardware, although a Supermicro vendor can help you find alternatives.
- More expensive for standard low-end servers. Supermicro customers don’t see major cost savings compared to big brands until they buy the more complex servers.
Pros
- Superior customization. Big brand servers typically come prebuilt and are difficult to customize. With a Supermicro server, you can optimize the hardware to fit your unique needs and avoid unnecessary costs.
- Affordable service plans. Tier 1 service plan costs often spike in their 4th and 5th years to motivate customers to upgrade. In contrast, Supermicro vendor service plans can be up to half the cost making long-term support more affordable.
- Excellent build quality. Just because you’re saving money doesn’t mean you’re sacrificing quality. Supermicro servers come with the same quality components as big brand boxes, giving you an unbeatable combination of cost and quality.
For complex server needs, Supermicro has the edge over its more expensive, less flexible competitors. But your analysis shouldn’t stop there. There are many more longer-term benefits to choosing Supermicro.
How Supermicro Servers Improve Business Performance
Supermicro is unique in that it’s a billion-dollar company committed to protecting the environment while innovating in its industry. Here are a few ways it’s doing that.
Supermicro is leading the way in green computing
Green computing saves your business money while saving the environment. How? Most green computing strategies are centered around saving resources, such as those needed to cool and power server farms. Supermicro servers leverage tactics like disaggregated server architecture, free-air cooling, pooled resources, and state-of-the-art rack scale design to drive down consumption and costs in the process.
Supermicro creates cutting-edge server technology
Supermicro continues to innovate the server industry. Advances in disaggregated server architecture make it possible to incrementally update servers by allowing system architects to replace individual components while keeping others like fans, and power supplies. In addition, updates to processors have resulted in gains of 10-15% in performance over the last few years. These advances have led to improvements in customer experience while simultaneously driving down costs.
Supermicro’s technology helps you stay compliant
Another advantage of working with Supermicro technology is that Supermicro works hard to meet the standards of countries from around the world. For example, the European Union started enforcing Lot 9 compliance on March 1, 2020, which puts requirements like minimum PSU efficiency and power factor limits on complete server and storage systems.
On Supermicro’s website, they outline how they comply with the Lot 9 regulation and where customers can find compliance info. This example shows how Supermicro helps its customers comply with government regulations to avoid hefty fines and restrictions on their operations.
How to Pick the Right Supermicro Server for Your Organization
While server technology is complex and highly technical, there are five steps you can take to simplify the selection process. Let’s look at these steps.
1. Analyze your needs
It’s important to start with what your organization needs to satisfy the current load on the server. Then, carefully consider the potential for growth for the next few years. While it’s not likely you can choose a system to last the next 50 years, you can build a modular system that can be upgraded incrementally before needing a complete overhaul.
2. Calculate your budget
Budget is second in this list because thinking of your budget first could hamper your team’s ability to consider the future. Thinking of your organization’s needs and future growth may motivate you to pursue a more robust system that may have higher upfront costs but results in lower long-term expenses.
3. Match your load to the right technology and server options
Now more than ever, it’s important that your team make strategic purchasing decisions. The best server technology should equip your team for current and future load expectations. Supermicro has ample options available to meet your business needs. Equus Compute Solutions has a team of experienced engineers that can help you make purchases to prepare you for current and future needs.
4. Consider the perks of a Supermicro Vendor
Whether you’re a reseller or work in a large organization with many technology needs you may wonder why you should work with a vendor versus working directly with the manufacturer. Quick issue response times, flexible warranty options, and lead times that consistently beat industry standards are just a few of the perks that your vendor can provide. How does this benefit your organization?
Customer-focused support:
- Easy platform and component replacement
- Access to a service repair depot
- 24/7 year-round helpdesk support with translators on standby
- White glove deployment
- On-site service technician support
- Local support for most US cities
Reduced lead times:
- Access to a secondary manufacturing queue
- Ability to source alternate component options
- Dedicated sales team to quickly send quotes and ensure product delivery
Configuration flexibility:
- Extensive component manufacturer relationships
- More opportunities to save on individual components
- Some vendors like Servers Direct provide additional configuration flexibility for Superserver and Ultraserver product lines
5. Get expert help
If you’re still struggling to make a decision, don’t leave this important investment up to chance. Talk to a server specialist who can help you find the best solution for your unique needs.
Future-proof Your Organization With Advanced Technology
The demand on your organization’s infrastructure will only increase as technology becomes more complex and user expectations increase. To keep up, data center operations must keep costs low while looking to the future. Supermicro works hard to be on the leading edge of server technology and leveraging the right technology can give you an advantage over the competition. If you’re thinking about upgrading your servers, talk to one of our specialists today.
Server experts are available to assist you by emailing sales@www.serversdirect.com or by calling direct at 800-576-7931
Whitebox Server Advantage
Why White Box Servers Beat The Big Brands
While big-name companies build their servers to high standards, they can’t do much configuration
White box (unbranded) servers use the same or superior components as big-name manufacturers, but come with customized capabilities at lower cost. No longer synonymous with rickety garage-builds, today’s white box servers offer top-quality hardware with customer-specific testing—a combination that high-volume brands like Dell EMC, Hewlett Packard Enterprise (HPE) or Lenovo can’t compete with. So how did white box servers finally get the edge over the big players? By using software to virtualize hardware.
Customized quality
While big-name companies build their servers to high standards, they can’t do much configuration. White box servers are assembled with components from market-leading suppliers and companies can tailor the builds and testing, paying for only the features they need. Plus, with new open source management software the cost over time of owning white box servers is much lower than branded boxes.
Service plans at half the price
Now that white box server quality matches or exceeds that of branded boxes, the potential cost savings on maintenance contracts are huge. Many white box companies offer remote support as well as 3-to-5 year service plans guaranteeing next-day onsite support, and these plans are often half the price of comparable brand-name contracts.
Logos reigned throughout the 90s and early aughts because configurations and bundled features assured consumers that their servers were reliable. The downside to all that predictability is that consumers paid for features they didn’t need and wound up locked into exploitative service contracts.
Big-brand service plans are comprehensive because their failures are comprehensive. Unlike custom-configured white boxes, in-house technicians can’t easily swap out failed parts in branded boxes, which means that even minor problems become major pains.
Most big brands sell three-year maintenance coverage at a reasonable price, then hike the cost of a fourth year of coverage—sometimes by three times as much as the original maintenance plan. This pressures customers into buying new hardware with fresh maintenance plans since it’s cheaper than repairing their existing servers.
How VMware leveled the field
In 1999, young software company VMware released VMware Workstation, a desktop virtualization package that allowed users to run several different operating systems on their desktop via virtual machines (VMs). The technique proved that software could virtualize hardware with powerful results, and led to a value shift: software now mattered more than hardware when it came to versatility and performance. Software-defined applications and virtualized servers build the reliability into the software—the software is designed to expect hardware outages and maintain the necessary service levels when it does happen. And because virtual servers aren’t tied to proprietary hardware, they can run on lower-cost white boxes.
In the intervening years, VMware has enabled millions of virtual machines and continues to work on virtualizing all types of hardware, including servers, networking and storage—moving the entire industry towards the Software Defined Data Center (SDDC) model. An SDDC is a completely virtual data center in which all elements of infrastructure – central processors (CPU), security, networking, and storage – are virtualized and delivered to users as a service without hardware vendor lock-in.
With software-defined architectures now ruling data centers, companies don’t need consultants to install and configure hardware. You can use an SDDC strategy to define applications and all of the resources you need, like computing, networking, security, and storage, and group the necessary components together to create an efficient operating environment.
Flexible, fast, and secure
While VMware led the shift to SDDCs, white boxes can run any virtualization, from Red Hat to kernel-based virtual machines (KVMs). Some white box servers can also support OpenBMC, a project within the Linux Foundation Collaborative that allows open-source implementation of the baseboard management controller (BMC) firmware.
Industry-leading companies, including Facebook, Google, Intel, Microsoft, and IBM, have been collaborating with OpenBMC and are developing their own open firmware versions. LinuxBoot is another advanced firmware project that gives white boxes an edge. LinuxBoot improves boot reliability by replacing closed, lightly tested firmware drivers with hardened Linux drivers. Industry leaders implementing large server networks use LinuxBoot to ensure that their unique basic input output system (BIOS) is secure, reliable, robust, and offers lightning-fast boot speed.
What is JBOD?
Got a growing data center? JBOD can simplify your storage.
 Seagate EXOS E 4U106 JBOD
Seagate EXOS E 4U106 JBOD
As data centers continue to grow, companies are looking for an option that lets them store the most data in the least amount of space—all at the lowest price. For many use cases, such as data archiving and video surveillance storage, JBOD is the simplest and most effective solution.
What is JBOD?
JBOD is an acronym for “just a bunch of disks” or “just a bunch of drives.”
Sometimes referred to as an expansion unit, JBOD is a simple, cost-effective way to add high-density data storage to a system by connecting multiple hard drives and housing them within a single chassis enclosure. It is an easy-to-manage, extremely reliable storage solution for companies with growing data centers.
“Think of JBOD as a bank vault for your data,” says Servers Direct Solutions Project Manager Jeff Salo. “It’s the safest and most efficient way to have on-premise storage.” Since the JBOD chassis is designed for drives only, it’s not competing for power or airflow with other hardware like motherboards and CPU.
A JBOD enclosure can be configured in JBOD or passthrough mode to support software file systems like ZFS and Storage Spaces. JBOD can also connect to controllers from popular manufacturers like LSI and Microsemi for hardware RAID management. Learn more about the different RAID setups here.
What are the benefits of JBOD?
In addition to being cost-effective and highly reliable, JBOD provides a host of other benefits, including:
- Minimal footprint with maximum storage space
- Integration with new or existing servers
- High performance with hardware RAID 50 or 60
- Compatibility with Linux software RAID file systems like ZFS, Gluster, and BTRFS
- Easy access to hot-swappable drive bays
- Independent scaling of storage and compute
- High availability support
- Expanded storage for Windows, Linux, and VMware servers
How can you use JBOD?
JBOD is a great solution for any enterprise that needs local storage expansion without the high cost of adding multiple servers. JBOD can add anywhere from hundreds of TB to multiple PBs of data storage.
A few examples of data storage scenarios that JBOD works well for include:
- Data backup and archiving
- Security and surveillance
- Media storage
- Replacing tape drives
- High availability and data protection
When should you use JBOD alternatives?
JBOD has high capacity, so it works well when large amounts of offline data need to be stored. But the tradeoff is low performance, which means JBOD is not necessarily a good option for primary storage. If your capacity needs aren’t huge and you need high performance, another solution would be better.
Conclusion
The right storage partner will ask about the amount of space, level of performance, and redundancy you need. Based on your answers, they’ll recommend the appropriate quantity of drives, type of JBOD, and the best software to manage it.
Whether you need to expand your current server capacity or are looking to implement an all-new solution, it is important that you carefully select the right solution. A partner like Servers Direct can help you get the right JBOD configuration for your needs and budget.
When you get in touch with Equus, we’ll ask about the amount of space, level of performance, and redundancy you need. Based on your answers, we’ll recommend the appropriate quantity of drives, type of JBOD, and the best software to manage it.
To learn more about what we can do with JBOD, chat now with our team.
See our Seagate JBOD configurations here.

GPU Server for AI
How to pick the best GPU server for Artificial Intelligence (AI) machines
What is a GPU and how is it different from a CPU?
The central processing unit, or CPU, can be thought of as the brain of a computing device. Despite the growth of the computing industry, today’s CPUs remain largely the same as the first CPUs to hit the market, both in terms of design and purpose.
CPUs typically handle most of the computer processing functions and are most useful for problems that require parsing through or interpreting complex logic in code. CPUs can perform many complex mathematical operations and manage all of the input and output of the computer’s components. This makes the CPU slow, but able to perform very complex computations.
While the CPU is the brain of the computer, the graphical processing unit, or GPU, is the computer’s eyes. GPUs have been specially designed to perform certain types of less complicated mathematical operations very quickly, enabling time-sensitive calculations, like those required for displaying 3D graphics.
The GPU has thousands of processing cores, which, while slower than a typical CPU core, are specially designed for maximum efficiency in the basic mathematical operations needed for video rendering. In other words, a GPU is essentially a CPU which has been designed for a specific purpose: to perform the computations needed for video display.
GPUs process simpler operations than CPUs, but can run more operations in parallel. This makes GPUs faster than CPUs for simpler mathematical operations. This feature of GPU makes it attractive for a wide range of scientific and engineering computational projects, such as Artificial Intelligence (AI) and Machine Learning (ML) applications.
GPU Computing
But because of the GPU’s versatility in advanced computational projects, it can be used for much more than video rendering. GPU computing refers to the use of a GPU as a co-processor to accelerate CPUs, which can serve a variety of applications in scientific and engineering computing.
GPUs and CPUs can be used together in what is known as “heterogeneous” or “hybrid” computing. GPUs can be used to accelerate applications running on the CPU by offloading some of the computer-intensive and time-consuming portions of the code. The rest of the application still runs on the CPU.
From a user’s perspective, the application runs faster due to the parallel processing — a GPU has hundreds of cores that can work together with the fewer cores in the CPU to crunch through calculations. The parallel architecture incorporating both CPU and GPU is what makes hybrid computing so fast and computationally powerful.
GPU for AI applications
A computer’s processing power, in the past, has relied on the number of CPUs and the cores within each CPU. However, with the advent of artificial intelligence (AI), there has been a shift from CPU to GPU computing. AI has made GPU useful for a variety of computational tasks.
Machine Learning (ML) is an AI technique that uses algorithms to learn from data and intuit patterns, allowing the computer to make decisions with very little human interaction.
Deep Learning is a subset of ML which is used in many applications including self-driving cars, cancer diagnosis, computer vision, and speech recognition. Deep Learning uses algorithms to perform complex statistical calculations on a “training set” of data. The computer uses ML principles to learn the training set, which allows the computer to identify and categorize new data.
How do GPUs assist Deep Learning number crunching? The training process for Deep Learning involves calculating millions of correlations between different parts of the training set. To speed up the training process, these operations should be done in parallel.
Typical CPUs tackle calculations in sequential order; they do not run in parallel. A CPU with many cores can be somewhat faster, but adding CPU cores becomes cost-prohibitive. This is why GPU is so powerful for AI and specifically ML applications. The GPU already has many cores because graphics displays also require a multitude of mathematical operations every second. For example, Nvidia’s latest GPUs have more than 3500 cores, while the top Intel CPU has less than 30. These GPU cores can run many different calculations in parallel, saving time and speeding up the training process.
Like graphics rendering, Deep Learning involves the calculation of a large number of mathematical operations per second. This is why laptops or desktops with high-end GPUs are better for Deep Learning applications.
How can I benefit from AI-powered by GPU processing?
Businesses can benefit from AI, particularly ML, in a variety of ways. ML can be used to analyze data, identify patterns, and make decisions. Importantly, the information gleaned from ML can be used to make smart data-driven predictions in a variety of contexts. For example, e-commerce websites use ML to offer predictive pricing, which is a type of variable pricing which takes into account competitors’ prices, market demand, and supply.
ML solutions can also help eliminate data entry and reduce costs by using algorithms and predictive modeling to mimic data entry tasks. Customer support, personalization, and business forecasting are other potential enterprise benefits of AI.
Should you shift to GPU?
Data is the main driver of decisions for businesses today. Without data-driven analyses such as those made possible by AI, ML, and Deep Learning, businesses would not be able to identify areas of improvement. ML can improve the way your business relies on data for insights, which can improve the day-to-day operations of your organization.
Custom GPU Server Configurations for your AI Needs
Artificial Intelligence and its subsets, Machine Learning and Deep Learning, can streamline operations, automate customer service, perform predictive maintenance, and analyze huge quantities of data, all to boost your bottom line.
But many AI applications need specialized computing environments in order to perform the same operations on repeat —enter custom GPU server configurations. The thousands of small cores on a GPU server means AI apps can analyze large data sets, fast. Below, we round up the best GPU server configurations for your AI tasks.
Single root vs. dual root
Most GPU servers have a CPU-based motherboard with GPU based modules/cards mounted on that motherboard. This setup lets you select the proper ratios of CPU and GPU resources for your needs.
Single root and dual boot are two types of configurations which differ in terms of the makeup of the GPUs and the CPUs on the motherboard. In a Single Root configuration, all of the GPUs are connected to the same CPU (even in a dual CPU system). In a Dual Root setup, half the GPUs connect to one CPU and the other half connect to a second CPU.
The main advantage of Single Root is power savings over time compared to Dual Root. On the other hand, Dual Root has more computational power but consumes more energy.
The best kit for AI beginners
For companies new to AI applications, a custom Tower GPU Server with up to five consumer-grade GPUs can provide a rich feature set and high performance. The Tower GPU Server offers added flexibility through a mix of external drive configurations, high bandwidth memory design, and lightning-fast PCI-E bus implementation. This setup is ideal if you want to experiment with Deep Learning and Artificial Intelligence.
Ready to launch? Upgrade your servers.
Once you’re confident in your AI application, move it to a GPU server environment that uses commercial-grade GPUs such as the Nvidia Tesla™ ;GPUs. The added cost of commercial-grade GPUs like the Nvidia Tesla™ ;translates to added enterprise data center reliability and impressive performance—which are vital features if you’re getting serious about AI.
If you need quick calculations on big data
A 1U server with 4 GPU cards using a single root is ideal for NVIDIA GPUDirect™ RDMA Applications and AI neural network workloads. Powered by a single Intel® Xeon® Scalable processor, this type of server greatly reduces the CPU costs of the system, letting you spend more on GPUs or additional systems.
If you have both computing-intensive and storage-intensive application, look for a 2U dual CPU with 3TB of memory and 12 hot-swap drive bays (144TB), along with 2 GPU cards using dual root architecture. This 2U GPU server supports Deep Learning and Artificial Intelligence applications that require fast calculations on big data sets. Dual Intel® Xeon® Scalable CPUs with high core counts can be used to maximize compute power.
If you need high-performance production
Many high-performance production-level AI applications need 8 or 10 GPUs in the server, which a 4U rackmount chassis can accommodate. A dense 10 GPU single root platform can be optimized for Deep Learning and Artificial Intelligence workloads. Each GPU in this server is connected to the same CPU using PCIe switches to handle the connectivity. Many of the latest Deep Learning applications use GPUDirect™ RDMA topology on single root systems to optimize bi-directional bandwidth and latency.
Want expert advice on your server configuration?
Call the Servers Direct team at 1.800.576.7931, or chat with a Technical Specialist here. Our engineers will help you build a customized solution that meets your performance and budget requirements. We ship within 4-7 business days.